About a week ago I made a typo when writing a message in Discord and it led me down a rabbit hole that revealed dark secrets about markdown. Mainly that it’s broken.
The typo itself was pretty simple. When italicizing a word by enclosing it in “*“, I hit space before I typed the closing “*” instead of afterwards. The result was something like *hello *world rather than *hello* world. Discord, as it turns out, was wholly unprepared for this kind of typo and the final rendered text completely omitted the space.
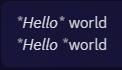
Italics markdown

The case of the missing space
Interestingly, it looks like this behavior is limited specifically to italics, as neither bold nor bold italics show the same behavior.
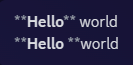
Bold markdown
Bold, brash, and beautiful
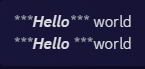
Bold Italics markdown

A third joke about text formatting
I don’t know about you, dear reader, but I would think that whatever system is parsing the text into HTML tags would be consistent between these. The fact that it isn’t makes me think there’s something deeply wrong happening here.
“Surely,” I thought, “surely this isn’t the tip of the iceberg”
So I did the obvious next step and wrote a little C# program to enumerate all possible variations of several test cases and spit them out into the console.
Because this Textvestigation® as I almost immediately decided to call it was centered around missing spaces, the test cases are also focused around how spaces are treated on the leading and trailing ends of annotated text. Each test covered a specific annotation character and some number of repetitions of that annotation up to a maximum of 3, which I believe is the most Discord allows.
// The possible annotation characters
{ "*", "_", "|", "~" }Each test contained four cases, each with identical text (“one two three”) wherein the second word, “two”, was surrounded with the annotation being tested. (E.g. “one *two* three“) The space before and after “two” was either inside or outside the annotation. With two possible states and two sides of the word for those states, there are four possible cases:
Case 1: “one *two* three“
Leading space: Outside annotation
Trailing space: Outside annotation
Case 2: “one *two *three“
Leading space: Outside annotation
Trailing space: Inside annotation
Case 3: “one* two* three“
Leading space: Inside annotation
Trailing space: Outside annotation
Case 4: “one* two *three“
Leading space: Inside annotation
Trailing space: Inside annotation
Do note that this notation of in in, in out, etc. is used in the test case outputs (Some of which are shown below) to signify which case is being shown.
In theory, all of these test cases should look identical because it shouldn’t matter if the space is bold or italic or not. The parser should pull the text inside of the annotation and it should have whatever text formatting applied to it as-is without modification to the text itself.
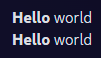
My plan was to simply copy the console output from my IDE and paste it into a Discord message to check the cases. As it turns out, Discord’s text parsing is also broken in a way that makes that not possible. Some of Discord’s annotations carry their effects over to new lines and some don’t. Italics, for example, do not carry over line-to-line whereas bold and bold italics do carry their effects over.
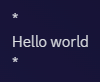
Italics markdown
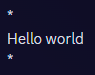
The rendered(?) text
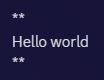
Bold markdown
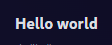
The rendered text
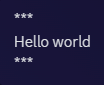
Bold Italics markdown

The rendered text
This immediately led to problems with the test cases as annotations from previous cases would sometimes and unpredictably carry over to the following lines and cause problems there. It’s great for finding problems and way less great for actually knowing where the problems are.
So now instead of a nice, simple bit of C# I need a full and complete Discord bot to send these test cases line-by-line to avoid problems with annotation carry-over. Fortunately for me (and you, dear reader) Discord bots are simple enough to set up that I don’t feel the need to detail it here. Suffice it to say it was an annoying addition to the problem but not prohibitively so.
Now that I had usable results I could finally see the unhinged things Discord’s markdown parser was doing.
Here are some of the choice cuts

Italics via the “*” annotation is absolutely falling apart. If you get it even remotely outside of a happy path it refuses to work.

Bold via the “**“annotation is working exactly as I would expect. This is the gold standard that the other cases absolutely do not match.

Bizarrely, using “****“, which is more annotation characters than is intended to be supported, hides all of the annotation characters and appears to be the same formatting as bold text.
I would’ve expected perhaps normal text if the first “**” annotation connected to the “**” immediately following to produce an empty section of bold text on either side of “two”
Another possibility would be something like “one *two* three” if it stopped consuming “*” after finding three of them.
Instead it looks like maybe it tried to bold the text twice, which is not something anyone would ever want.

Italics via the “_” annotation should provide an identical output to the “*” case and yet here we are.
The trailing space isn’t being omitted, which is nice, but it doesn’t make me feel particularly great about how this was all implemented that it’s possible for these two annotations to produce different results while applying the same format.

Spoilers via three or more “|” annotations appear to parse the first “||“, as an annotation, then include any remaining “|” in the spoiler itself, and then close the spoiler with the first “||” it finds afterwards. This leads to asymmetric outputs that leave any extra trailing “|” outside of the spoiler.
This same behavior is shared with the “~” annotation used for struck text.
Worse yet, this all appeared to be broken on mobile as well, but in new and innovative ways. For the sake of ever finishing writing this post, I won’t list them all here, but there are similar but different problems with italics.
After some digging into old Discord blog posts, I found that Discord uses Khan Academy’s simple-markdown as the basis for its rich text parsing. The goal of simple-markdown is to be easy to use and easy to extend. It appears that the way they’ve decided to go about making an easy-to-extend parser is by having the entire thing work off of huge Regex patterns. Those are always a hit with maintenance programmers.
Let’s take a look at the italics Regex pattern from simple-markdown as an example:
// only match _s surrounding words.
"^\\b_" +
"((?:__|\\\\[\\s\\S]|[^\\\\_])+?)_" +
"\\b" +
// Or match *s:
"|" +
// Only match *s that are followed by a non-space:
"^\\*(?=\\S)(" +
// Match at least one of:
"(?:" +
// - `**`: so that bolds inside italics don't close the
// italics
"\\*\\*|" +
// - escape sequence: so escaped *s don't close us
"\\\\[\\s\\S]|" +
// - whitespace: followed by a non-* (we don't
// want ' *' to close an italics--it might
// start a list)
"\\s+(?:\\\\[\\s\\S]|[^\\s\\*\\\\]|\\*\\*)|" +
// - non-whitespace, non-*, non-backslash characters
"[^\\s\\*\\\\]" +
")+?" +
// followed by a non-space, non-* then *
")\\*(?!\\*)"It looks like lists are likely to be the cause of a lot of our problems here, as “ *” is being specifically prevented from closing italics in case it might be, instead, a list. The approach being taken here is to wholly decouple the different parts of the parser so that each regex pattern has to be built with all of the other patterns in mind. These aren’t stand-alone patterns and rules, they’re deeply interconnected but indirectly so such that writing the patterns is very error-prone. This approach would, I have to assume, make it harder and more time consuming to add additional markdown rules as it would require you to go back and update any of the previous patterns that might conflict in some way.
I’ve considered writing my own patterns and opening a pull request with them, but the prospect of writing that many interdependent Regex patterns sounds like way more headache than it’s worth.
The great news is that while investigating this I found that basically every other markdown parser I could find had some kind of similar problems.
As an example from the top of the Google results for “markdown editor”, StackEdit.io shows different, often conflicting formatting in the editor vs the rendered output.




As it turns out, markdown is a very poorly defined, poorly regulated dumpster fire of a standard that desperately needs someone to fix it. The official line on markdown, written by markdown co-creator John Gruber, contains several vague and interpretation-requiring elements that lead to conflicting implementations.
The folks over at CommonMark are attempting to create an improved version of the Markdown specification, available here, that seeks to correct issues in Gruber’s 2014 description. While their spec sheet is surely more comprehensive and has been adopted by several major companies and groups, it still leaves something to be desired.

I wish I had some words of wisdom to close this post out with but the main thing I’ve taken away from this is a deep sense of unease around the state of in-line text formatting.
If I have to live with this knowledge, now so do you.
Leave a Reply